原文:Demonstration of Damson: Differential Privacy for Analysis of Large Data
摘要—— Damson为生物医学研究的结果提供较强的隐私保护,是一种强大的新型工具。Damson基于差分隐私算法,即使攻击者掌握了大量的背景知识,也无法从公开的结果中推断出某个个体是否存在。Damson支持生物医学研究中常见的各种分析任务,包括直方图,边缘,数据立方体,分类,回归,聚类,点对点选择计数。此外,Damson包含一个高效的查询优化引擎,从而在获得高精度的分析结果同时最小化隐私成本。
简介
隐私问题已经成为研究者获取生物医学数据的主要障碍。简单的去身份识别方法,如去掉个体的名字和ID,很难保证足够的隐私保护。主要的原因是,攻击者虽然不能直接从公开的数据中恢复个体的身份信息,但他往往可以结合额外的背景知识去重新识别个体的身份。数据安全研究人员已经想出了一些具有鲁棒性和通用性的重识别算法。比如,[13]的作者仅仅通过从IMDB网站(www.imdb.com)公开的数据集中获取背景知识,就可以在Netflix电影评级网站(www.netflixprize.com)的匿名数据中成功重识别个体。
而且,对于一些生物医学的数据集,哪怕仅仅是从数据中导出来的统计结果,也可能会泄露隐私信息。一个著名的例子是全基因组关联研究(GWASs)——生物信息学的一个热门话题,研究一群患同种疾病的病人(比如糖尿病)中的DNA样本,希望能发现疾病与人类DNA中的某些特定的部分(叫做SNPs)之间的联系。一种最近研发的攻击[7],通过目标个体的DNA样本和从HapMap公开的仓库(www.hapmap.org)中获取的参考人口(比如欧洲、亚洲等等),就可以重识别出该个体。一种改进的攻击[16]更是威胁到未来发布的所有GAWS成果,这些数据在现在的生物医学研究期刊上很容易就可以找到。
回应上述问题,近期掀起一股热潮研究隐私数据的发布和分析。早期的方案使用简单的方法实现数据匿名化,比如k-匿名(k-anonymity)将每个个体隐藏在一个新的群中,这个群包含k个难以区分的新个体[17]。这些方法难以对抗拥有背景知识的攻击者,比如,当攻击者知道了群中的k-1个个体,k-匿名便失去了作用。而且,因为没有形式上的隐私保证,即使攻击者没有掌握任何背景知识,满足k-匿名的算法是否真的可以保护个体的隐私,这里依然存在疑问。举例来说,l-多样性(l-diversity)[11]解决了这个问题,攻击者可以从缺少多样性(比如群中k个个体都患同种疾病)的k-匿名群中推断出敏感信息,且l-多样性本身也在不停的被挑战和补充[9]。这些问题激发出一些更有效的解决方法,这些方法基于更强大的方案,有稳定,可验证的隐私保证。
差分隐私[5]就是这么一种方法,它保证攻击者无法推测出个体的存在与否,即使他已经获得了数据集中其余所有个体的准确信息。推测的难度由参数ε决定,ε也叫做隐私预算(privacy budget)。实现差分隐私的一种流行方法论是将随机噪声注入到公开的统计查询结果中[6]。这里的查询是指任意有唯一输出的函数,涵盖了最常见的一些生物医学分析任务。根据组合律,应答隐私预算为ε1,.....,εn的多重查询q1,......,qn,分别满足(ε1+......+εn)-差分隐私。
设计差分隐私方案的主要难题是最大化查询准确率。虽然存在一种通用方案理论上可以应答所有查询,但在实际应用时准确率往往表现的很糟糕。因此,过去为了解决多种类型的查询往往需要提供更多的方案。在ADSC我们建立了Damson系统[3],整合了大量的差分隐私算法去执行常见的生物医学研究任务。Damson的贡献是巨大的。第一,Damson包含了一些新的算法;第二,差分隐私的不同解决方案往往对数据和查询有不同的前提和要求,因此将它们都整合到一个系统中非常不容易;第三,高效率、高准确率、低隐私预算需求地应答多重查询极具挑战性,必须具备高效的查询优化引擎;最后,Damson有相当高的使用价值,因为它能够为基于敏感数据的生物医学分析提供强隐私保障,而此前的方法都很难做到。
本次演示聚焦于Damson的两个主要方面,1)Damson在多种常见的生物医学分析任务中表现如何;2)Damson在这些任务中是如何利用最少的隐私代价实现较高的准确率。接下来的II、III节会分别详述Damson在这两方面的设计。
差分隐私下的生物医学分析
在这里我们演示Damson中已实现的7种不同类型的分析任务:直方图(histogram)、数据立方体(data cube),边缘(marginal)、分类(classification)、聚类(clustering)、回归(regression)和点对点选择计数(ad-hoc selection-count)。
-
直方图(Histogram)
直方图通过一组不相交的块来概括数据的分布,每个块代表在对应属性取值范围上的记录的数目。图1a是一个样例数据集,图1b是建立在Age属性上的直方图(提取自参考文献[20])。直方图中的每个块(以图1b中年龄40-50为例)包含了源数据(图1a)中对应记录的数目(4个)。图1b是一种等宽直方图,每个块代表相同的属性取值间距。同时,通常来说最精确的直方图有着最好的粒度,比如让每个块只代表一个年龄。但是,从我们的演示中[20]看到,由于向公布的直方图中注入了额外的噪声,差分隐私下最好的直方图通常既不是等宽的,也没有最好的粒度。特别指出,合并连续的块会带来信息损失,但同时也会减少等量的差分隐私所需的额外噪声。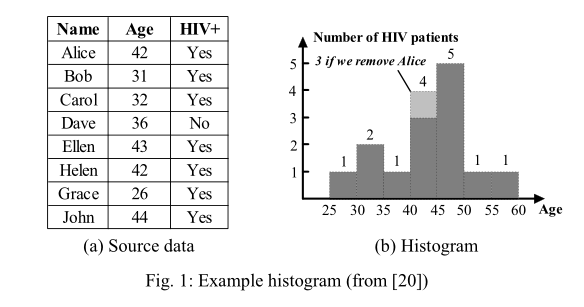
直方图发布的一个主要技术难题是,除了其公布的统计数值外,直方图的结构也可能泄露敏感数据。举例说,在图1中,如果我们去掉Alice的记录,优化直方图的结构有可能不同。Damson使用[20]提出的动态规划算法会自动建立最好的差分隐私直方图。此算法会根据差分隐私的需要在块计数和直方图结构中都注入随机噪声。
-
数据立方体(Data Cube)
数据立方体是在多维数据上执行OLAP操作的重要工具。图2显示了一个示例计数数据立方体,取自[4]。源数据(称作事实表fact table)包含3个属性,性别(Sex)、年龄(Age)、工资(Salary)。数据立方体包含多个汇总表,称作方体(cuboid)。举例说,图2b显示了工资属性上的方体,每行记录包含了事实表上特定工资值(如10-50k)元组的计数(3个)。一个方体也可以涵盖多个属性,如图2d中包含了年龄和工资两个属性,其中每行记录包含了事实表上特定的年龄-工资组合(如年龄:21-30,工资:10-50k)的元组的计数(3个)。注意到工资方体可以通过年龄-工资方体计算得出,只需将后者中所有相同工资的记录合并。一般来说,一个涵盖集合A的“较粗”的方体总是可以通过一个包含A子集的“较细”的方体推导出来。事实表本身可以看做是“最细”的方体,可以导出其它任意的方体。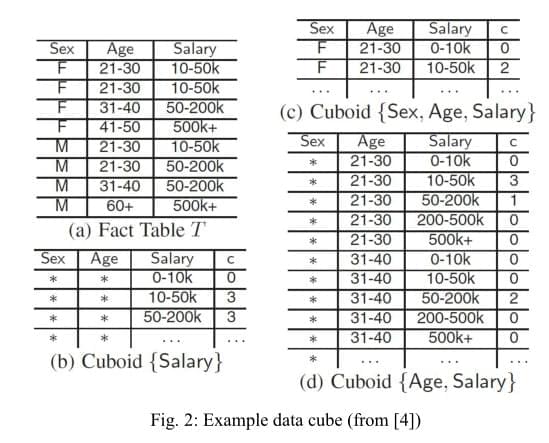
数据立方体的发布有两个难题。第一是确定应该发布哪些方体。发布一个方体需要占用一部分的隐私预算,会使到其它的方体噪声增多(即准确率下降)。另一方面,如果我们不直接发布方体C,而是通过更细的方体C'去导出C,那么由于噪声的累积,C的准确率将会很糟糕。举例说,假如我们忽略工资方体本身,而用年龄-工资方体表计算出工资方体,后者计数的准确率将会比前者的低很多。(译者注:原文这里的前者和后者是反过来的)因为年龄方体中的每个计数都是从年龄-工资方体中多个记录中统计出来的,噪声也会随之积累。第二个难题是保持关联方体间的一致性。例如,假设同时发布年龄方体和年龄-工资方体,因为两者添加的噪声是不相关的,年龄方体中的一条记录与年龄-工资方体中对应记录统计出来的结果会不相同,这导致了不一致性问题。Damson优雅的解决了这两个问题,其数据立方体模块会自动选择一组方体发布,最大限度地提高整体精度,并对不同方体强制执行一致性。
-
边缘与朴素贝叶斯分类(Marginal and Naive Bayes Classification)
边缘相当于数据立方体中的方体,它是一张表,对给出的属性集,统计事实表上每种可能的属性组合的记录数。数据立方体与边缘的主要区别是,数据立方体是公布了所有的方体,而边缘发布则通常会先给出一组属性组合,然后只公布相对应的边缘。比如,在图2中,我们可能会只想分别发布年龄-性别边缘和年龄-工资边缘。差分隐私下发布数据立方体的难题同样存在边缘发布中,也就是,发布最优的边缘和强制他们的一致性。然而,这些问题在边缘发布中相对没那么重要,因为边缘发布通常只会发布少量的边缘,而不像数据立方体一样发布全部的方体。同时,发布的边缘集合通常是基于一个更复杂的分析任务。朴素贝叶斯分类就是这样一种任务,其目的是使用其余的属性(称为特征属性)预测一个属性的值(称为目标属性)。具体而言,朴素贝叶斯分类可分为两个阶段,训练阶段和测试阶段。在训练的过程中,朴素贝叶斯计算出一个概率模型,记录目标属性和每个特征属性之间的相关性。虽然不同的特征属性也会表现出相关性,但朴素贝叶斯为了简化,忽略了此类相关性(因此称为朴素贝叶斯)。训练阶段生成的模型会用在接下来的测试阶段中,用于计算目标属性每个取值之间的可能性,然后取最大可能的取值。要使用朴素贝叶斯分析,我们需要发布m+1个边缘,m是特征属性的个数。这里包括了一个目标属性的边缘,其余m个分别是目标属性与其中一个特征属性组合的边缘。比如,假设工资是目标属性,性别和年龄是特征属性。朴素贝叶斯需要发布3个边缘,分别是工资边缘、性别-工资边缘和年龄-工资边缘。
在边缘发布中,一个共同的目标是最小化整体相对误差,而不是整体绝对误差[17]。这需要为较小的计数添加较小的噪声,较大的计数添加较大的噪声。这在差分隐私下实质上就是隐私预算的分配问题,因为注入较小的噪声需要占用隐私预算更大的一部分。主要的难题是预算分配过程本身也要以差分隐私的方式运行。Damson通过[17]提出的迭代方式解决此问题,高效率的找出最佳的预算分配,最小化发布边缘的整体相对误差,并且满足差分隐私要求。
-
回归(Regression)
回归分析在医学研究中尤其有用。例如,通过一些风险因子比如年龄、体重、病史等等去预测一个病人的诊断结果。Damson目前支持两种常见的回归分析:线性回归(linear regression)和逻辑回归(logistic regression)。前者试图在不同属性之间确定线性相关,而后者则类似于线性分类器。如图3a是一个线性回归的例子,其中包含两个属性:性别和医疗费用,围绕在直线附近的点是病例。线性回归的目标是找到一条线,到所有点的总距离最小。图3b是逻辑回归的一个例子,目的是区分出糖尿病人。这里有两个特征属性,年龄和胆固醇含量。逻辑回归在特征空间里(如年龄-胆固醇含量平面)确定的一条线,满足(1)线的一边有最多的糖尿病人,另一边有最多的非糖尿病人;(2)对于“糖尿病”的一边,离线越远的病人越可能患糖尿病,对于“非糖尿病”的一边,离线越远的病人越不可能患糖尿病。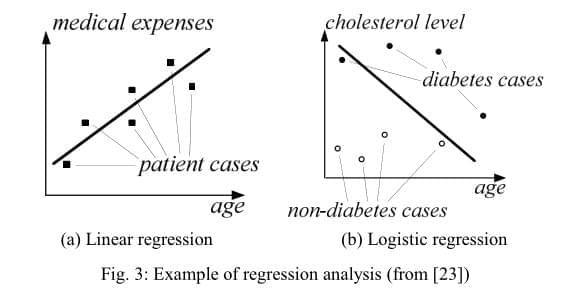
在差分隐私下进行回归比单纯的计数要复杂的多,因为很难确定满足私隐保证的噪声数量[1][23]。特别是,线性回归和逻辑回归都涉及到最优化程序(optimization program)。逻辑回归最优化程序的最优解并没有一个闭式数学表达式(closed-form mathematical expression),只能用数值表示,因此很难做敏感度分析。而尽管线性回归存在一个闭式最优解,但在此解上直接进行敏感度分析会导致敏感度过高,从而引起过高的噪声水平。
Damson通过函数机制(Function Mechanism)解决上述问题,向最优化程序上的目标函数注入随机噪声,而不是注入到函数的解上。如[23]所示,利用合适数量的训练样本,函数机制就可以使得Damson在低隐私预算消耗下实现高精度的回归分析。
-
聚类(Clustering)
给出一组数据点,聚类的目标是从中找出没有预定义的数据簇,满足此条件的相似的点属于同一个簇,不相似的点会被分到不同的簇中。Damson使用了一个简单但强大的聚类技术:K-means聚类。k-means被广泛用于大量的分析任务。k-means接收一个参数k,然后找出k个中心点,使到每个数据点到它最近的中心点的总距离最小。每个中心点形成一个簇,每个数据点属于离该点最近的中心点的簇。图4是聚类分析的一个例子,数据依据三个中心点进行聚类。注意中心点可以是任意的点,而不必是其中一个数据点。图中的三条直线表示不同聚类间的边界。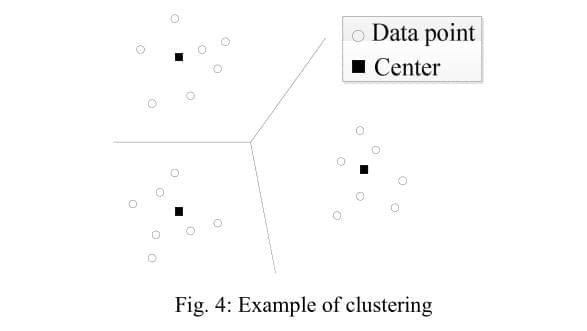
寻找k-means的最优解是一个著名的NP难题。而且,最优的k-means有较高的敏感度,需要大量的干扰,这样会使得结果几乎完全随机。对于差分隐私下的k-means聚类,Damson当前的做法是使用PINQ[12]中提出的迭代算法。虽然此算法没有提供任何的质量保证,但在实际应用中的表现通常都很好。当前正在改进Damson的k-means聚类模型,将使用有质量保证的新算法。
-
点对点选择计数(Ad-Hoc Selection-Count)
上述的每个分析都是为了解决某个具体的分析任务,这些任务在过去中都有明确定义并且经常用到,都是对整个数据集进行操作。在实际应用中,研究人员有时需要针对数据的某个子集进行点对点分析。Damson要处理一大类这样的分析,即范围计数查询,对落入用户指定的属性范围中的记录进行计数。举一个实际的例子,一间药物公司在展开临床试验之前,有时需要先知道一个地区(如新加坡)中是否存在充足的满足要求的病人。比如要求年龄在40-50岁之间,收缩压在120-140之间。不像直方图或者边缘一样有预先定义好的范围,这里的查询可以有任意的范围,可以选择任意的属性组合。Damson内部的解决方案是基于DP树结构[14](DP-tree Structure),有效地处理任意维度的范围计数查询。DP树超越了我们之前的方案Privlet[19][18],对于等量的私隐预算DP树有更高的准确度,尤其在更高维度的查询上。我们正在扩展Damson,使之不仅支持计数和范围,还支持集合(aggregates)和选择标准(selection criteria)。
Damson中的查询优化
传统来说,查询优化主要是为了节约运算时间。然而在一个符合差分隐私的系统中,查询优化还需要优化分析结果的准确率和隐私预算的消耗。Damson结合两大技术,分别针对批量查询和相对误差最小化。
-
批量查询过程(Batch Qurey Processing)
初次在[8]显示,相对于单独地应答,使用优秀策略应答批量线性查询的总体准确率要更高。所谓的策略这里是指处理不同组的查询,合并它们的结果去应答原始的查询。然而,[8]中提到的方案更倾于理论化,实际中甚至不能处理中等大小的数据集。Damson使用[22]提到的新方法解决此问题,该方法高效、可扩展,有效的找出最佳的策略。此方法的主要思想是找出可以近似地应答输入的策略,而不严格要求准确。这些近似的误差是可以控制的,而且相比注入到查询结果中的噪声,此类误差通常也是可以忽略的。这里将会演示由Damson计算出的策略查询,看看这些查询如何合并,以较少误差去应答原始的查询。 -
相对误差最小化(Raletive Error Minimization)
当前大部分满足差分隐私的解决方案都是去最小化查询结果的绝对误差。然而,对于大部分的应用,包括在II-C节讨论的边缘发布,最小化总体相对误差更有意义。直观上看,结果较小的查询对噪声更敏感。Damson结合iReduct技术[17]去实现相对误差最小化。除了差分隐私边缘计算的应用,damson还可以最小化批量点对点查询的总体相对误差,只需小心地为每个查询分配隐私预算。我们将展示Damson如何计算最佳的预算分配,使到输入查询的总体相对误差最小化。
结论
Damson在不侵犯个体隐私的前提下,帮助研究人员在敏感数据上进行常见的分析。我们将展示Damson如何支持各种各样的分析任务,从简单的任务如计数、直方图和边缘,到复杂的任务如分类和聚类。同时,我们将演示Damson如何利用低隐私损耗、低系统负担,高准确率的完成上述的这些任务。考虑到系统的优势,我们预计Damson将会被广泛的应用,特别是生物医学领域。
参考文献
- K. Chaudhuri and C. Monteleoni. Privacy-Preserving Logistic Regression. NIPS, 2008.
- K. Chaudhuri, C. Monteleoni, and A. D. Sarwate. Differentially Private Empirical Risk Minimization. Journal of Machine Learning Research, 12:1069-1109, 2011.
- Damson. http://differentialprivacy.weebly.com/
- B. Ding, M. Winslett, J. Han, and Z. Li, Differentially Private Data Cubes: Optimizing Noise Sources and Consistency. ACM SIGMOD, 2011.
- C. Dwork. Differential Privacy. ICALP, 2006.
- C. Dwork, F. McSherry, K. Nissim, and A. Smith. Calibrating noise to sensitivity in private data analysis. TCC, 2006.
- N. Homer, S. Szelinger, M. Redman, D. Duggan, W. Tembe, J. Muehling, J. V. Pearson, D. A. Stephan, S. F. Nelson, and D. W. Craig. Resolving Individuals Contributing Trace Amounts of DNA to Highly Complex Mixtures Using High-Density SNP Genotyping Microarrays. PLoS Genetics, 4(8), 2008.
- C. Li, M. Hay, V. Rastogi, G. Miklau, A. McGregor. Optimizing Linear Counting Queries under Differential privacy. PODS, 2010.
- N. Li, T. Li, S. Venkatasubramanian. t-Closeness: Privacy Beyond k-Anonymity and l-Diversity. IEEE ICDE, 2007.
- Y. Li, Z. Zhang, M. Winslett, Y. Yang. Compressive Mechanism: Utilizing Sparse Representation in Differential Privacy. WPES, 2011.
- A. Machanavajjhala, J. Gehrke, D. Kifer. l-Diversity: Privacy Beyond k-Anonymity. IEEE ICDE, 2006.
- F. McSherry. Privacy Integrated Queries. ACM SIGMOD, 2009.
- A. Narayanan, V. Shmatikov. Robust De-anonymization of Large Sparse Datasets. IEEE Symposium on Security and Privacy, 2008.
- S. Peng, Y. Yang, Z. Zhang, M. Winslett and Y. Yu. DP-Tree: Indexing Multi-Dimensional Data under Differential Privacy. ACM IGMOD, 2012, poster.
- L. Sweeney. k-Anonymity: A Model for Protecting Privacy. International Journal on Uncertainty, Fuzziness and Knowledge-Based Systems. 10(5): 557-570, 2002.
- R. Wang, Y. Li, X. Wang, H. Tang, and X. Zhou. Learning Your Identity and Disease from Research Papers: Information Leaks In Genome Wide Association Study. ACM CCS, 2009.
- X. Xiao, G. Bender, M. Hay, and J. Gehrke. iReduct: Differential Privacy with Reduced Relative Errors. ACM SIGMOD, 2011.
- X. Xiao, G. Wang, and J. Gehrke. Differential privacy via wavelet transforms. IEEE ICDE, 2010.
- X. Xiao, G. Wang, and J. Gehrke. Differential privacy via wavelet transforms. IEEE TKDE, 23(8):1200-1214, 2011.
- J. Xu, Z. Zhang, X. Xiao, Y. Yang, and G. Yu. Differentially Private Histogram Publication. IEEE ICDE, 2012.
- Y. Yang, Z. Zhang, G. Miklau, M. Winslett and X. Xiao. Differential Privacy in Data Publication and Analysis. ACM SIGMOD, 2012, tutorial.
- G. Yuan, Z. Zhang, M. Winslett, X. Xiao, Y. Yang and Z. Hao. Low-Rank Mechanism: Optimizing Batch Queries under Differential Privacy. PVLDB, vol. 5, 2012.
- J. Zhang, Z. Zhang, X. Xiao, Y. Yang and M. Winslett. Functional Mechanism: Regression Analysis under Differential Privacy. PVLDB, vol. 5, 2012.